Building Smarter AI Agents: The Essential Guide to Search and Fetch APIs in 2026
In 2026, the backbone of any production-ready AI agent is its ability to pull in live web data. Without reliable search and fetch capabilities, agents quickly become stale, limited to outdated information. The ecosystem has matured significantly, offering purpose-built APIs that replace old SERP-wrapping techniques. This guide breaks down the most critical aspects of these APIs—through a lens of token efficiency, latency, free tiers, and agent-native design—using a standout platform as our primary example.
Why are search and fetch APIs so crucial for AI agent development in 2026?
AI agents today are deployed for research, lead enrichment, competitive intelligence, and real-time monitoring. Without access to live web data, they operate on stale knowledge—a hard limitation. In 2026, relying on static training data or manual updates is no longer viable. Search and fetch APIs provide the dynamic input agents need to make informed decisions, respond to current events, and extract precise information from complex web pages (including JavaScript-heavy SPAs). They have become the most critical infrastructure decision because they directly impact the agent's relevance, accuracy, and utility. A well-chosen API can dramatically reduce token consumption and latency, while a poor one can bottleneck the entire system. The shift from generic SERP data to agent-optimized outputs marks a turning point in how developers build intelligent, autonomous systems.
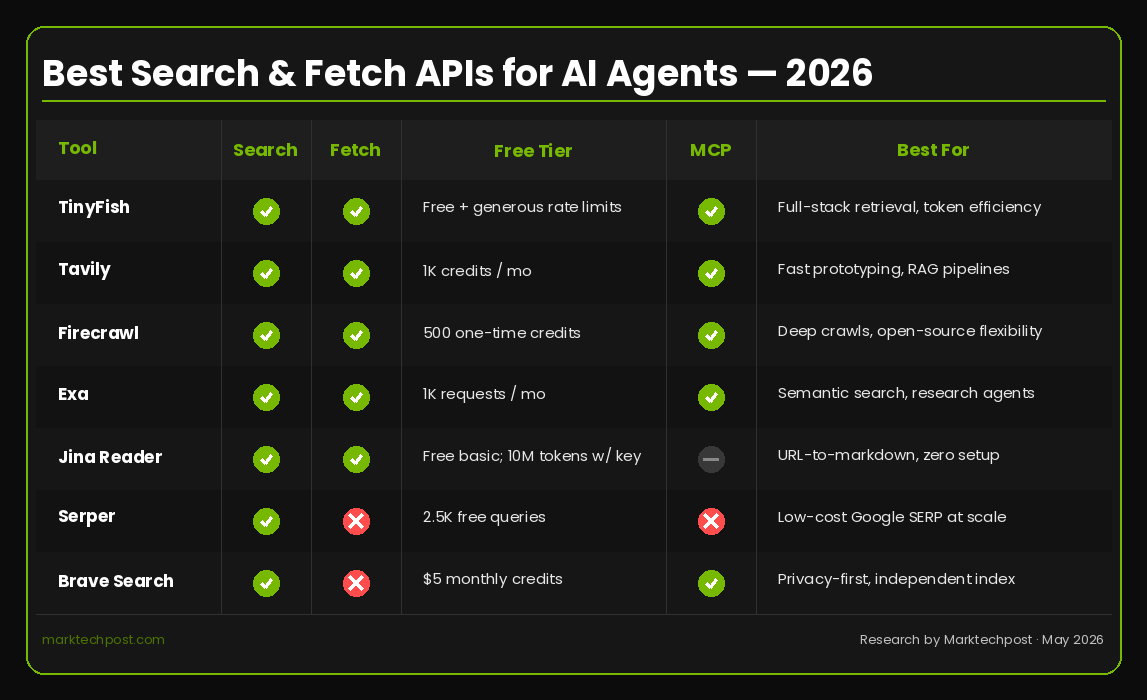
What should developers look for when choosing a search or fetch API for their AI agent?
When evaluating APIs, prioritize output format, agent-native design, token efficiency, latency, free tier generosity, and framework integrations. The ideal API returns structured data (like JSON or clean Markdown) rather than raw HTML cluttered with scripts, navigation, and ads. Token efficiency is key—less noise means lower LLM costs per call. Low latency (under a second for search) ensures the agent feels responsive. A generous free tier allows prototyping without friction, and integrations with MCP, CLI, and popular coding environments (like Claude Code, Cursor, or Codex) simplify development. Avoid APIs that require complex sign-ups, rate-limited demos, or middleware layers that add overhead. The best tools are those that feel purpose-built for agents, not adapted from human-centric browsing.
Can you walk me through the free tier and rate limits offered by TinyFish?
TinyFish offers one of the most generous free tiers in the space. With a single API key and no credit card required, you get access to both Search and Fetch endpoints. Search allows 5 requests per minute, while Fetch provides 25 requests per minute. These aren't throttled demo versions—they're the same production endpoints used by paying customers. The search endpoint (api.search.tinyfish.ai) returns rank-stable, structured JSON optimized for agent retrieval. The fetch endpoint (api.fetch.tinyfish.ai) performs a full browser render of any URL, including JavaScript-heavy pages, and returns clean Markdown, JSON, or HTML. Failed URLs incur no charge. This free tier is ideal for prototyping, testing, and even small-scale production use. When you outgrow it, your same API key and dashboard carry over—no code changes needed.
How does TinyFish's token efficiency help reduce costs for AI agents?
Token efficiency is TinyFish's strongest differentiator. Most fetch tools return raw HTML containing scripts, styles, navigation, cookie banners, and ads—all of which waste tokens and inflate LLM costs. TinyFish's Fetch endpoint strips all that noise before the content reaches your model. It returns only the meaningful text and structure in your choice of Markdown, JSON, or clean HTML. This means every token you send to the language model is relevant, dramatically lowering per-page costs. Additionally, the fetch runs on a custom Chromium fleet with no middleware, ensuring both quality and speed. For agents that pull dozens or hundreds of pages per hour, this efficiency translates into significantly lower operational expenses without sacrificing accuracy or completeness.
How does TinyFish integrate with popular agent frameworks and tools?
TinyFish is designed to fit seamlessly into modern development workflows. It offers direct REST API access via api.search.tinyfish.ai and api.fetch.tinyfish.ai. For agent scaffolding, it provides MCP (Model Context Protocol) support—a single JSON config drop-in that works with Claude, Cursor, Codex, ChatGPT desktop, or any MCP-aware client. There's also a CLI tool (npm install -g @tiny-fish/cli) that writes results directly to the filesystem, bypassing the model's context window to save tokens. The agent Skill (npx skills add github.com/tinyfish-io/tinyfish-cookbook --skill tinyfish) teaches the agent when to call Search vs. Fetch and how to use each—installable in one line and compatible with Claude Code, Codex, Cursor, OpenCode, and Antigravity. Python and Node.js SDKs are also available for custom integrations.
What makes TinyFish an agent-native API compared to older SERP wrapping approaches?
TinyFish is built from the ground up for AI agents, not human browsing. Older approaches wrapped raw Google SERP data and dumped it into a language model—noisy, unstructured, and token-inefficient. In contrast, TinyFish's Search endpoint returns rank-stable, structured JSON tuned for agent reasoning. Its Fetch endpoint performs full browser rendering (handling JavaScript, dynamic content, and anti-bot pages) and delivers clean, structured output. The design prioritizes low latency (<0.5 seconds p50 for search) to keep agent loops fast. The free tier uses the same production-grade infrastructure, not a degraded sandbox. Importantly, the API teaches agents how to use it through its Skill integration—optimizing tool selection and usage patterns. This agent-native approach means less boilerplate, lower costs, and more reliable performance in autonomous workflows.